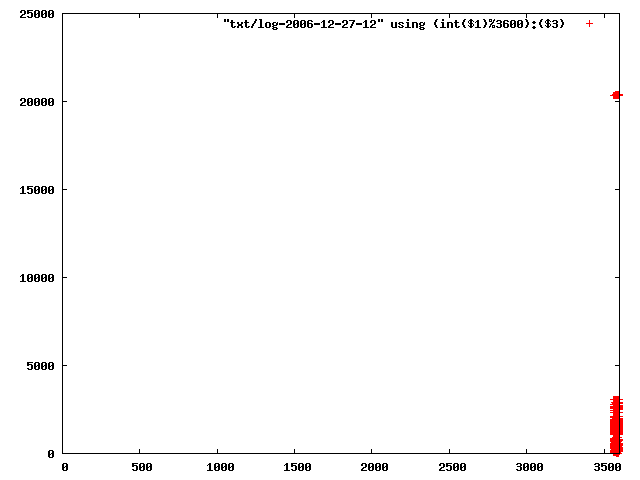
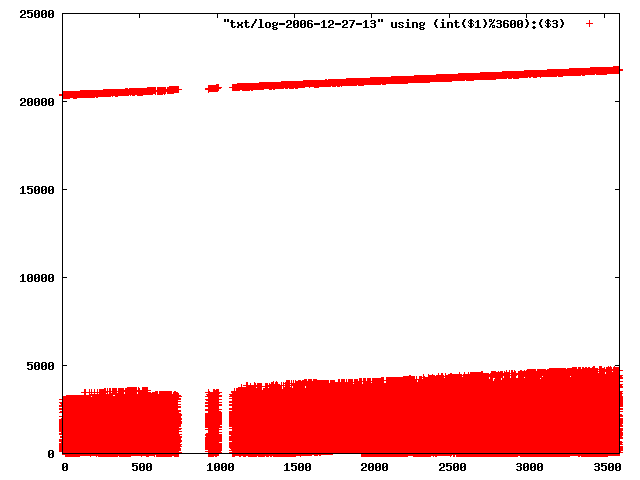
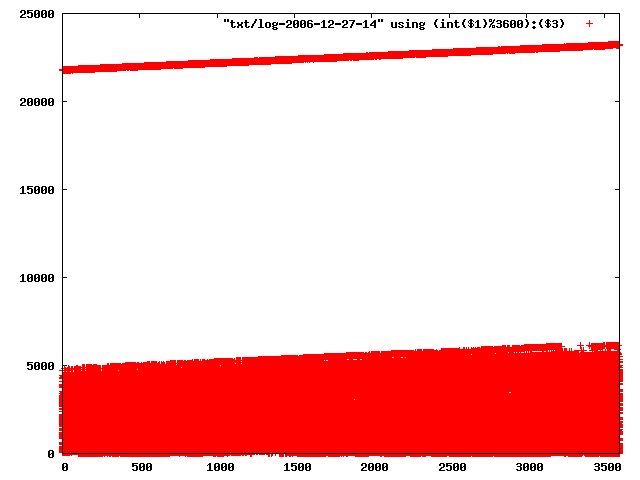
the xml logs are available from http://www.openbeacon.org/dl/23C3/sputnik-observations.xml.bz2.
dump -x -w 24 binlog/log-2006-12-27-13 -l 0xc5000 dump -x -w 24 binlog/log-2006-12-27-13 -o 0xc5000
compile rdlog.cpp with
g++ -O3 rdlog.cpp -o rdlog
find binlog -type f | xargs ./rdlog -v -stats -bytesthis will output statistics per byte, and per field of each binary logfile. when you pipe the output through sort and uniq, like this:
find binlog -type f | xargs ./rdlog -v -stats -bytes | sort | uniq -c | sort -r | head -20you will get a list of what fields are constant for all log frames.
at the bottom you will find under 'src ip' a list of used station ip addresses, save this list to 'stattionlist.txt' it will be used by the next steps to make sure every logfile uses the same translation of ip-address to station-id.
mkdir txt find binlog -type f | xargs ./rdlog -stations stationlist.txt -full txtthen use gengp.pl to generate a gnuplot script:
perl gengp.pl txt pngfull > txt2png.gp gnuplot tst2png.gpnow have a look at pngfull/lo/
note that some graphs have easily isolated lines split those off using:
mkdir horz find binlog -type f | xargs ./rdlog -stations stationlist.txt -split horz perl gengp.pl horz pnghorz > horz2png.gp gnuplot horz2png.gpthis generates 571 seperate files
now check pnghorz/lo/...
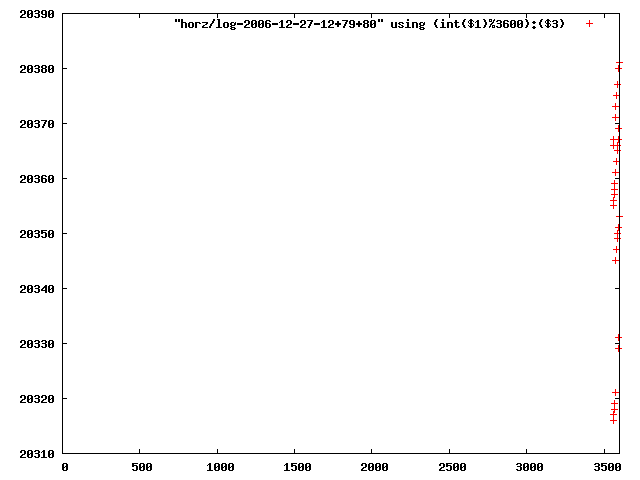
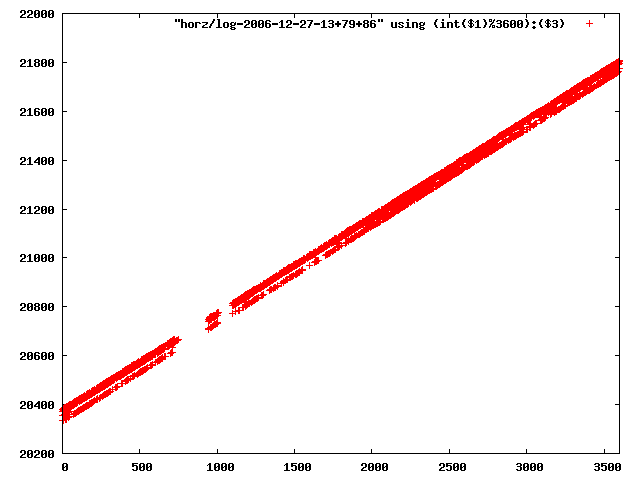
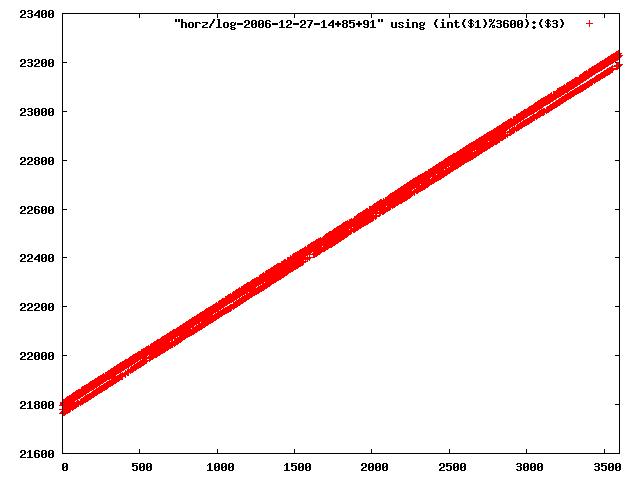
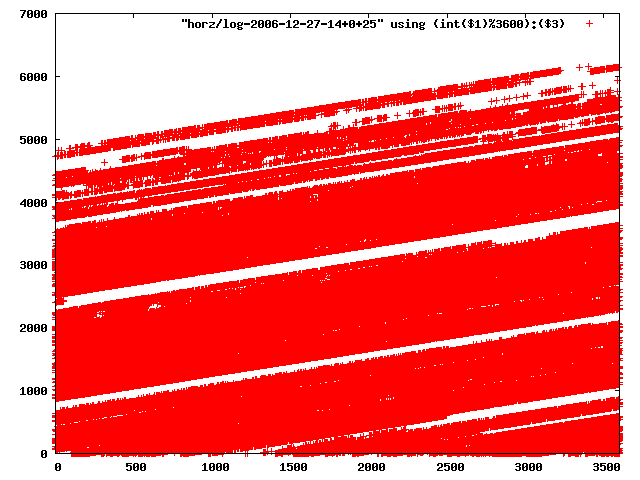
i manually selected several files of which i calculated the linear least-squares curve fit using lsq. see tstlsq.sh
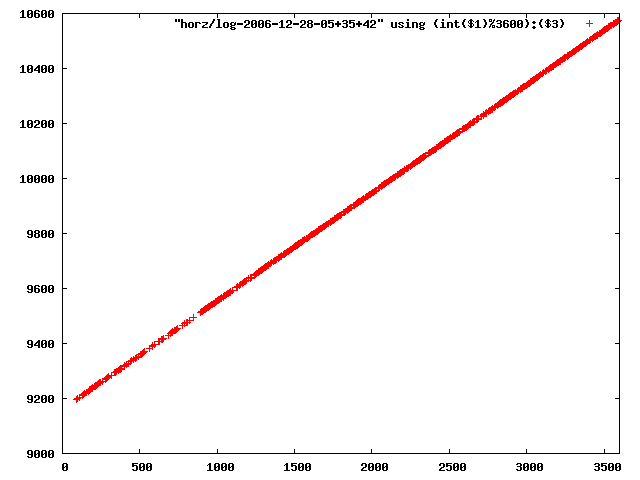
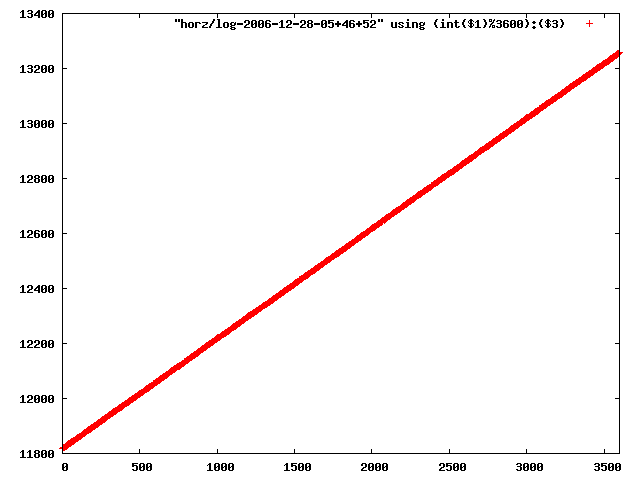
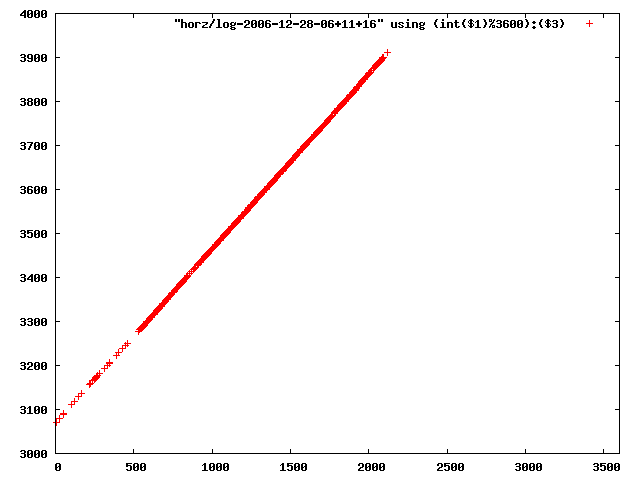
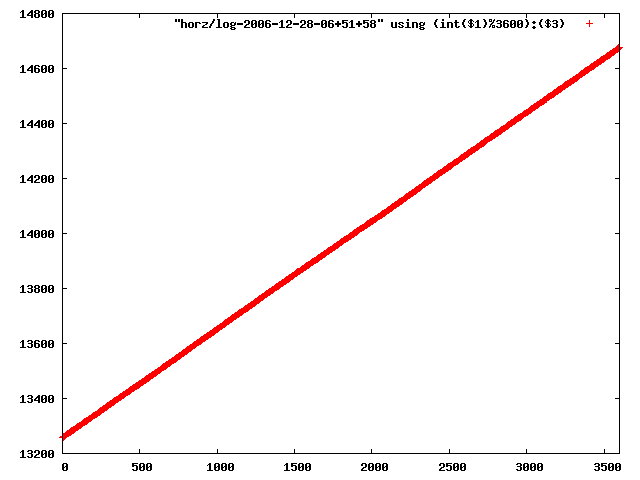
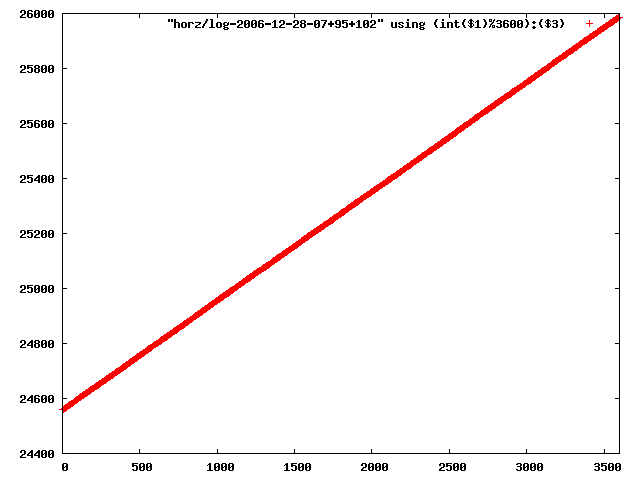
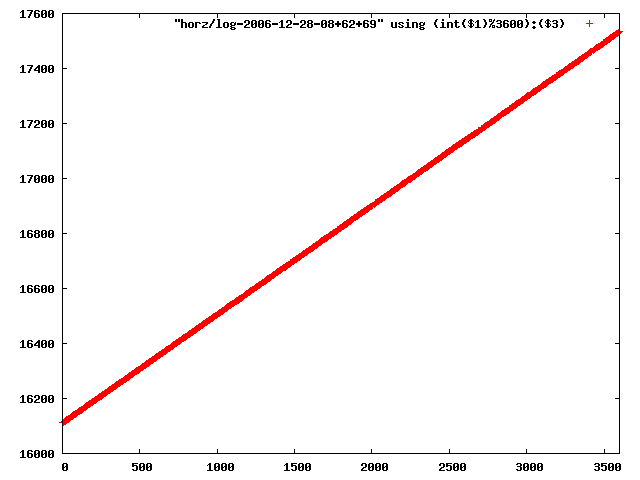
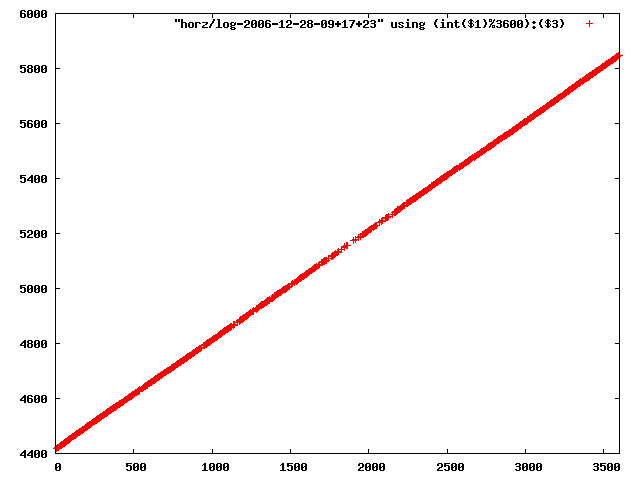
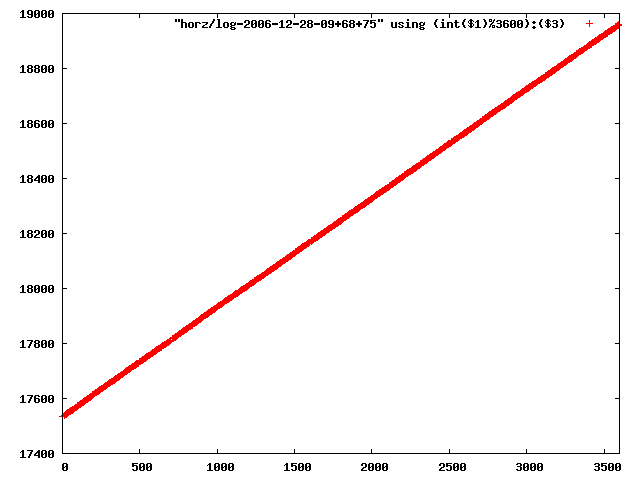
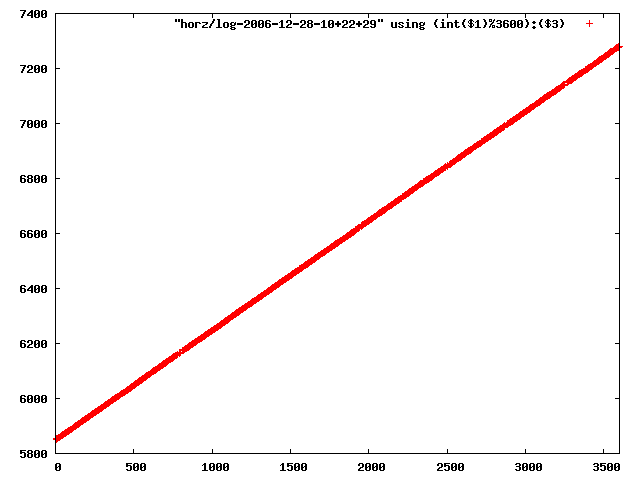
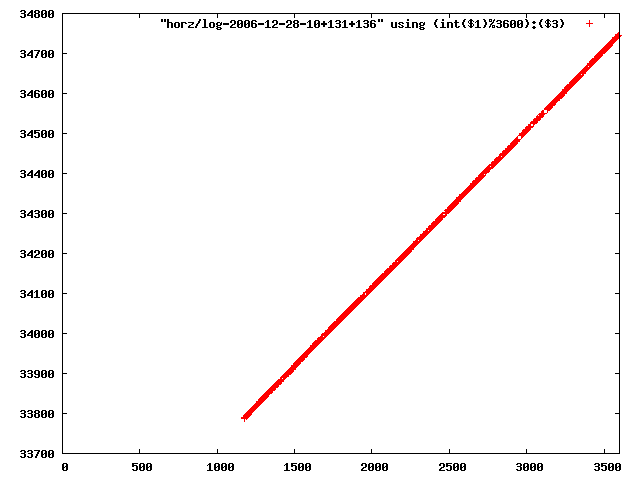
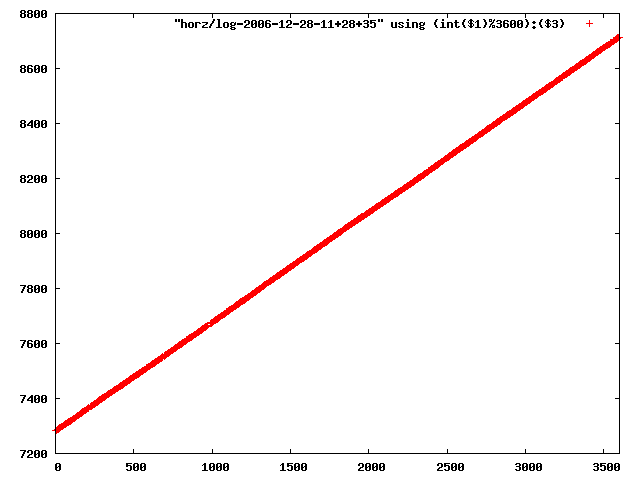
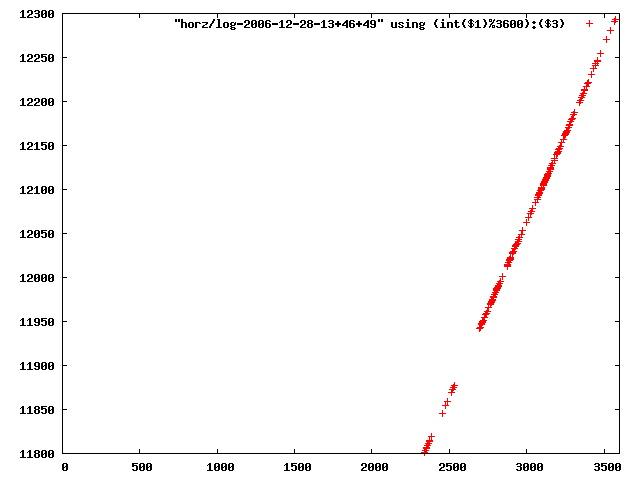
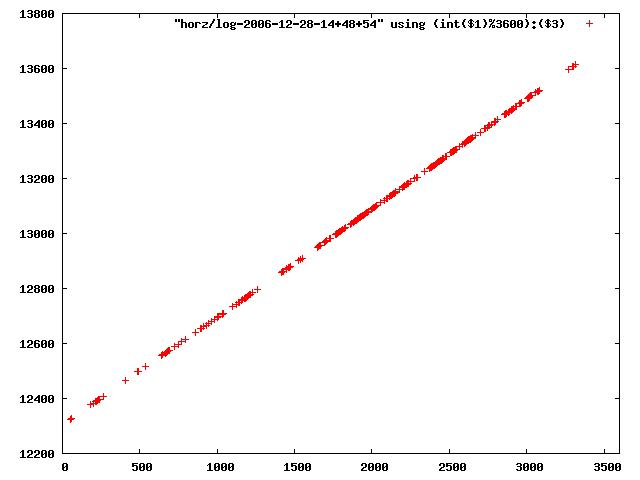
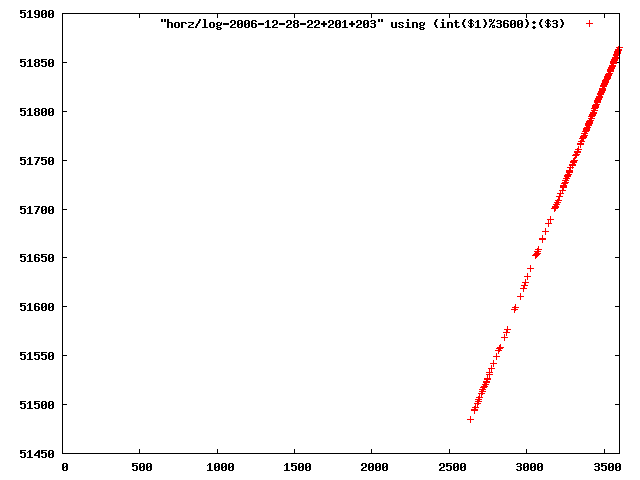
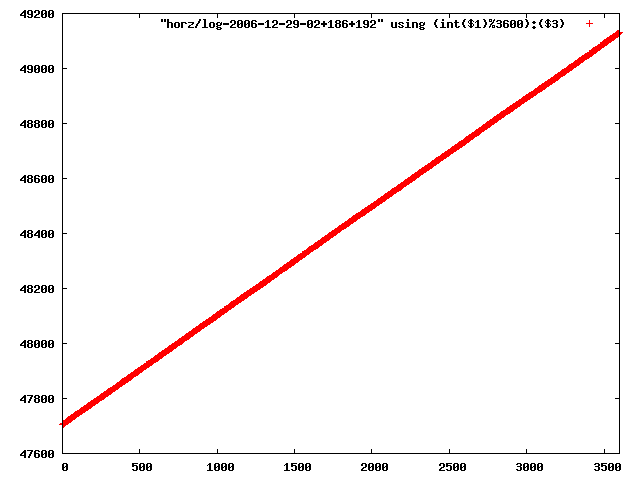
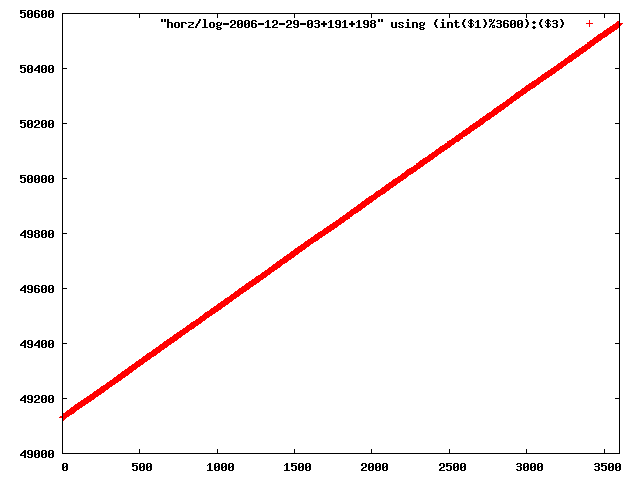
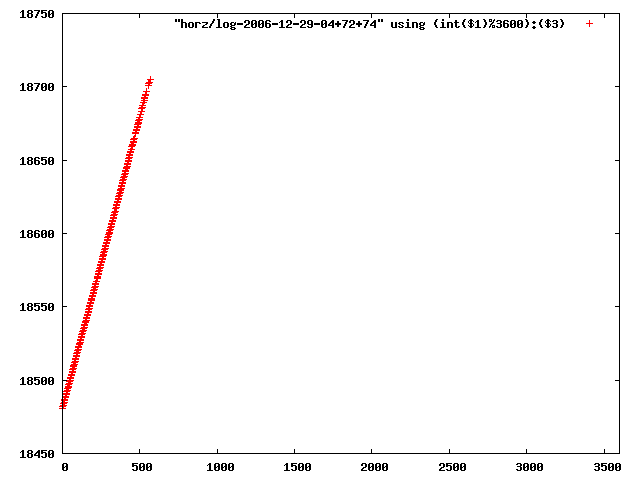
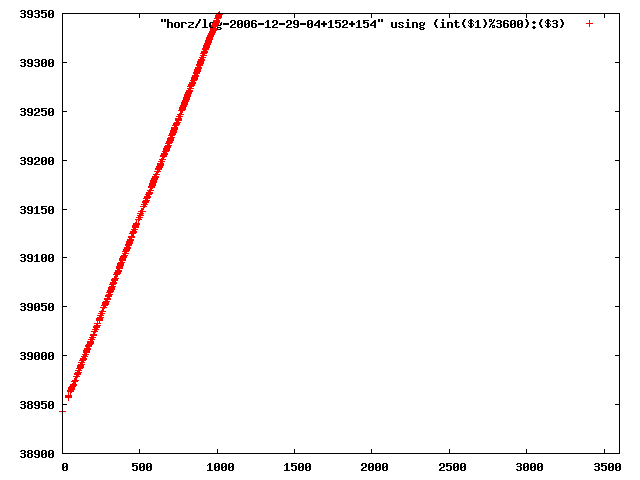
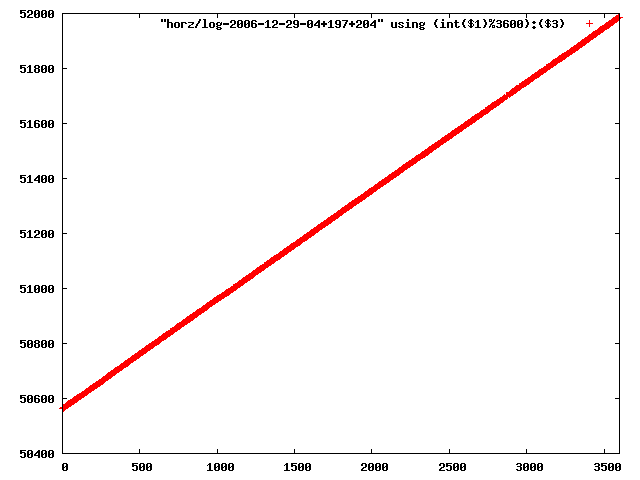
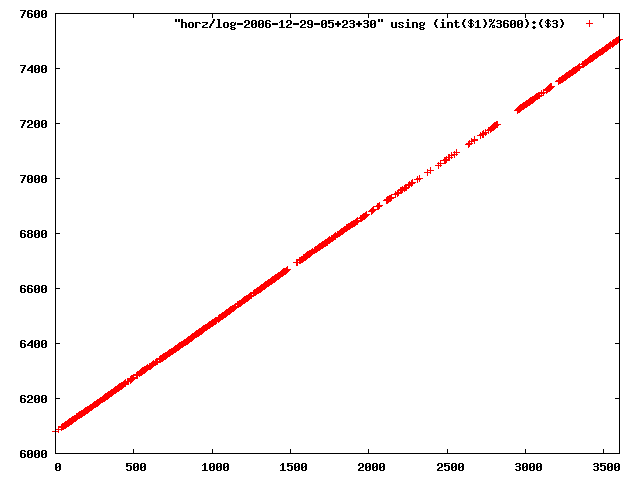
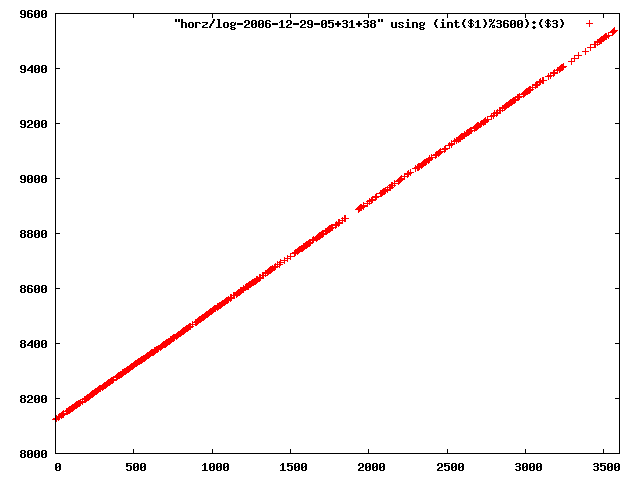
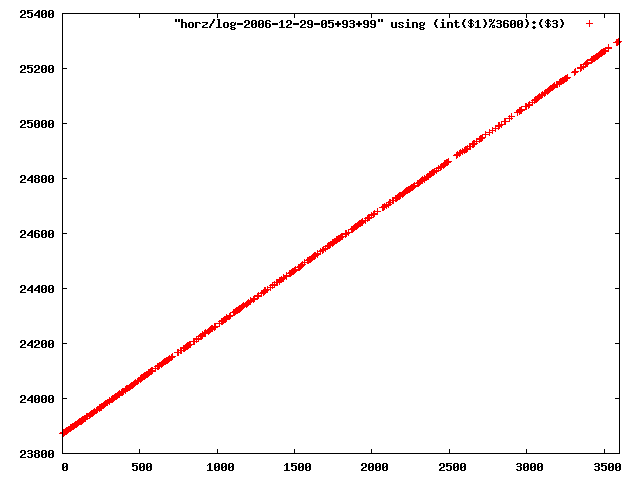
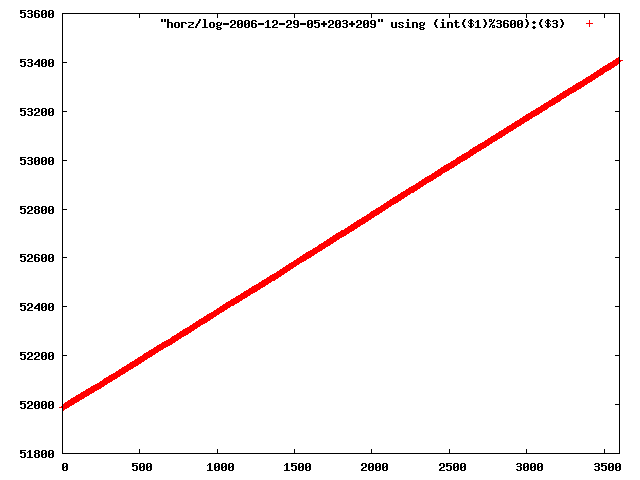
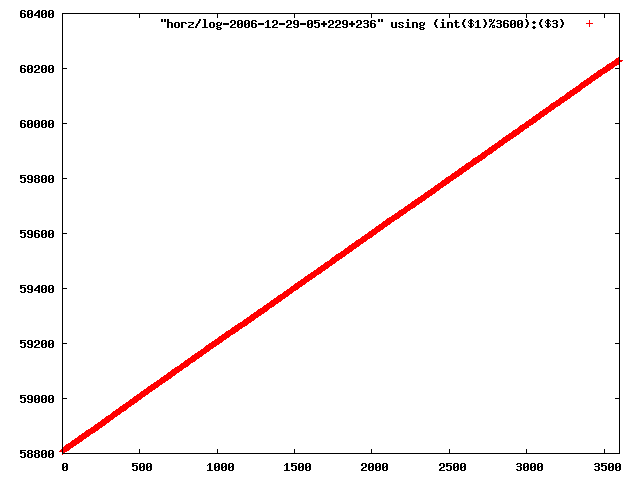
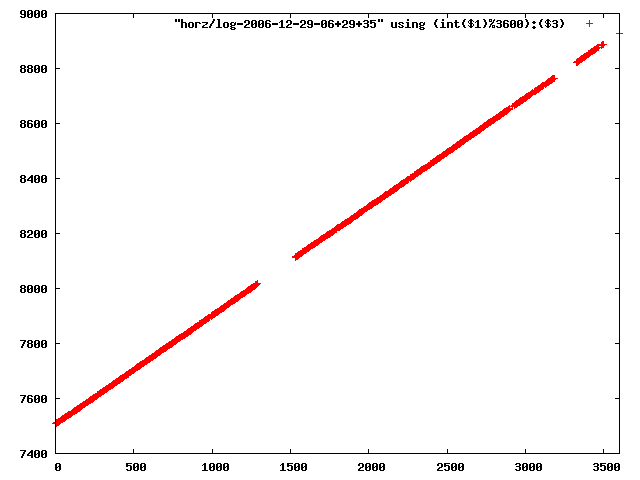
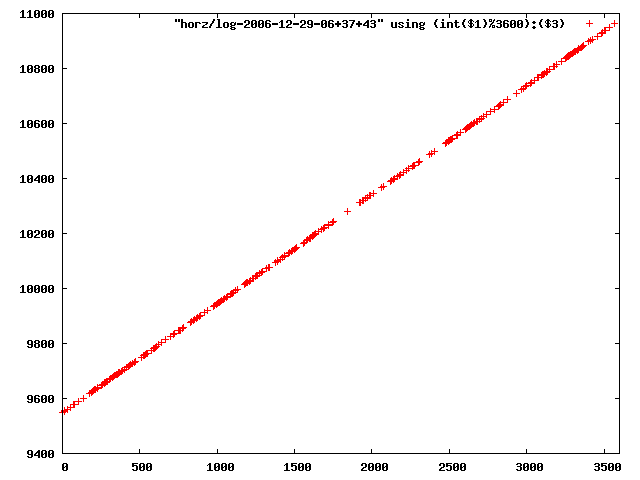
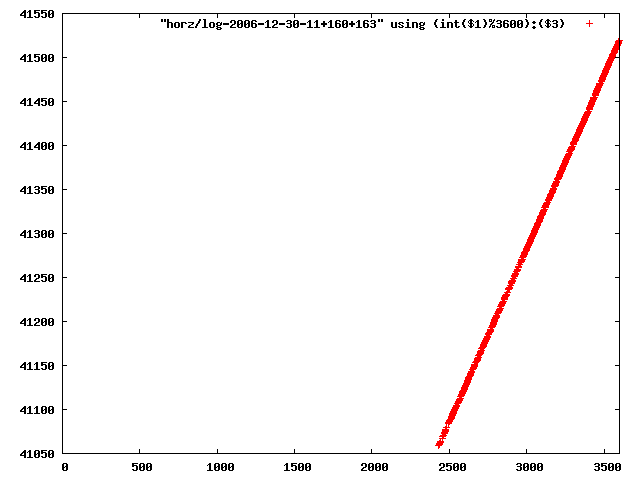
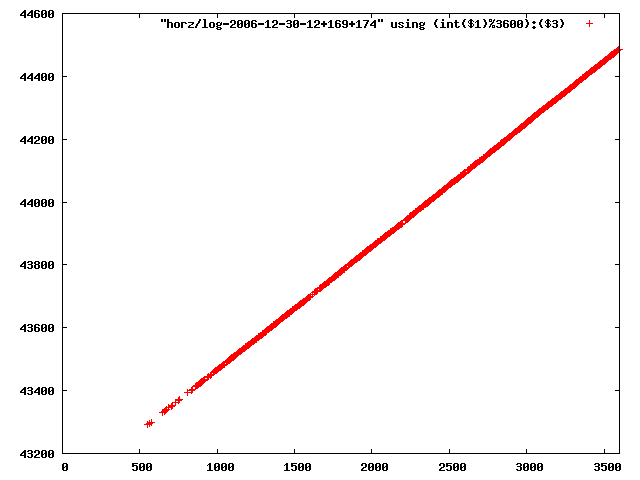
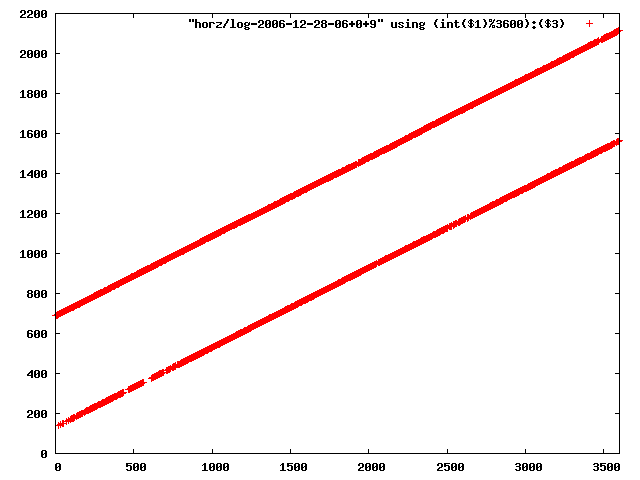
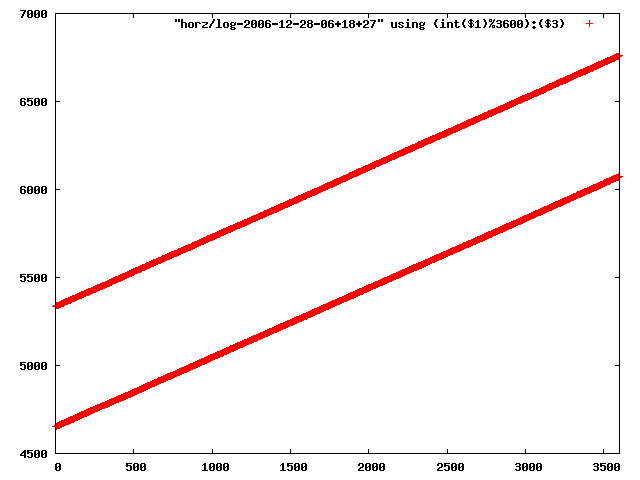
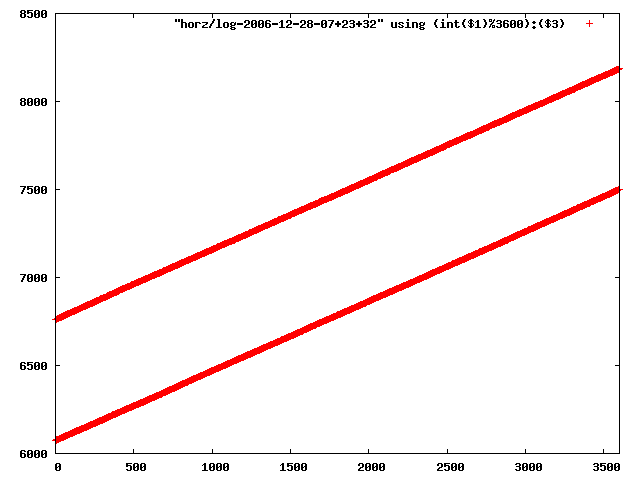
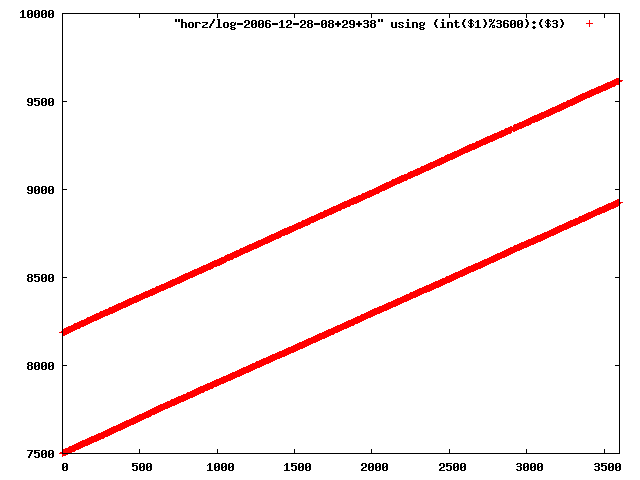
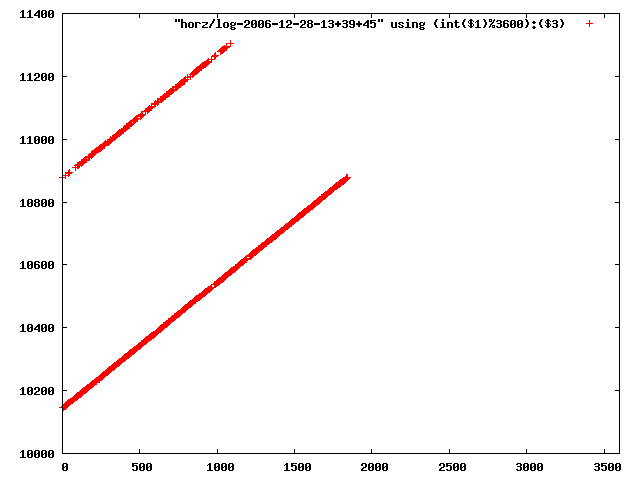
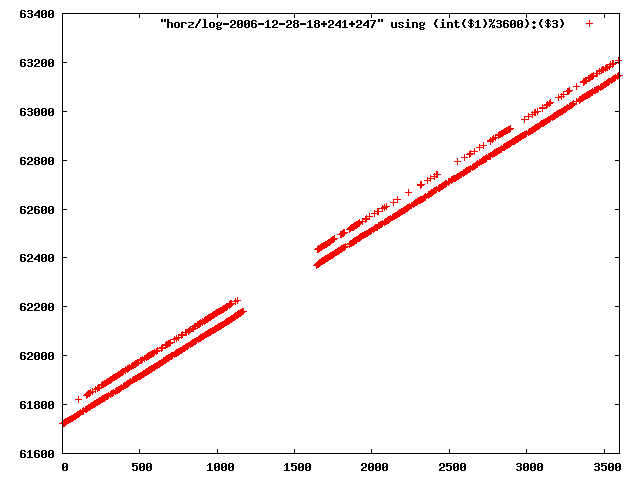
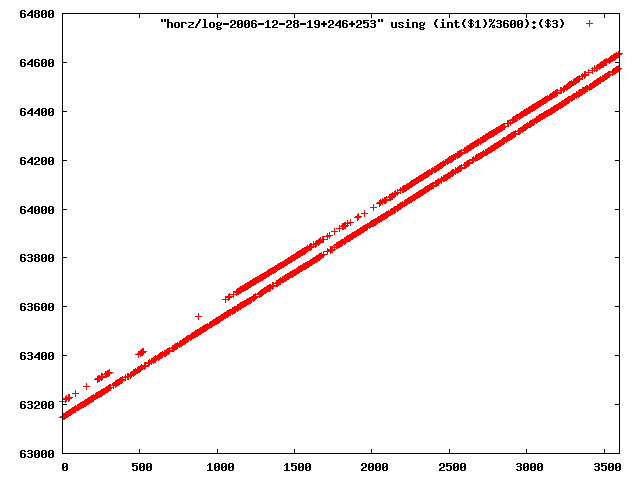
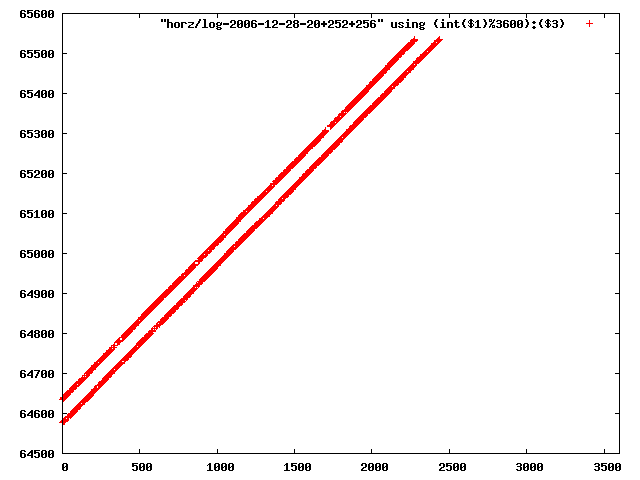
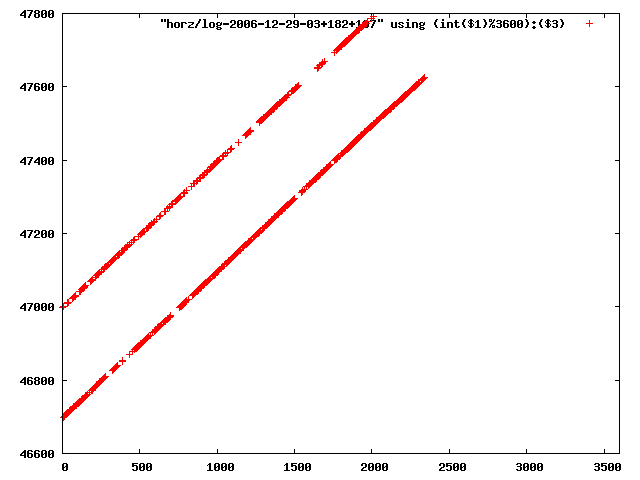
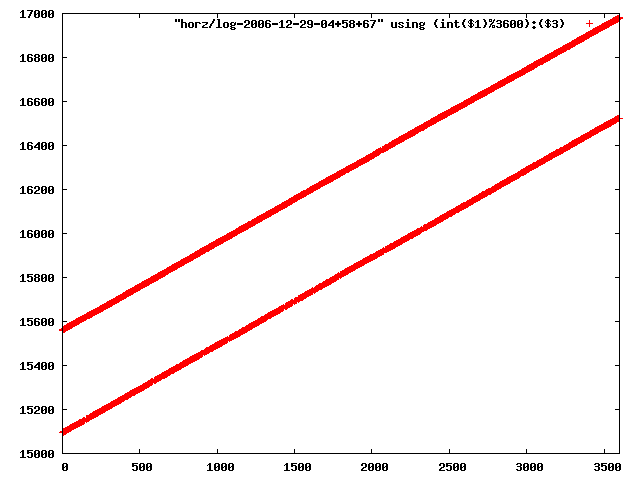
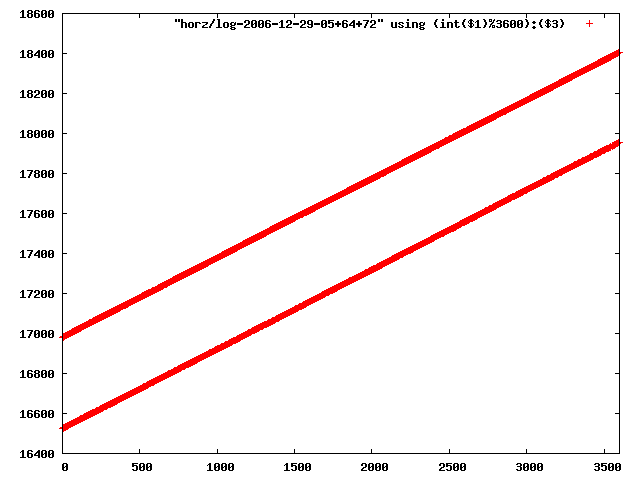
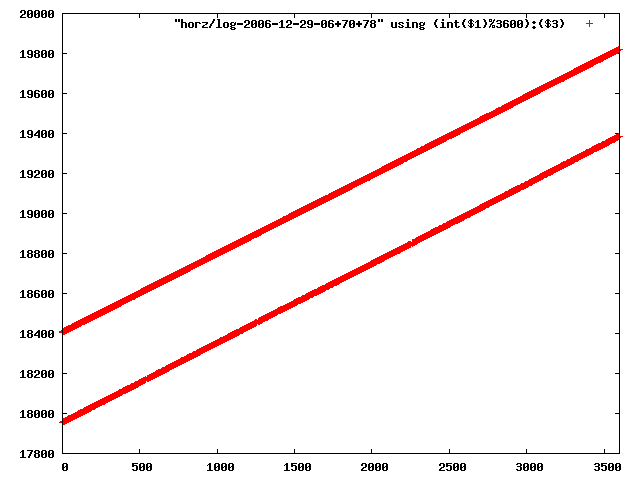
from this i concluded that a average slope of 0.396 was best
the above graphs rotated would look like this:
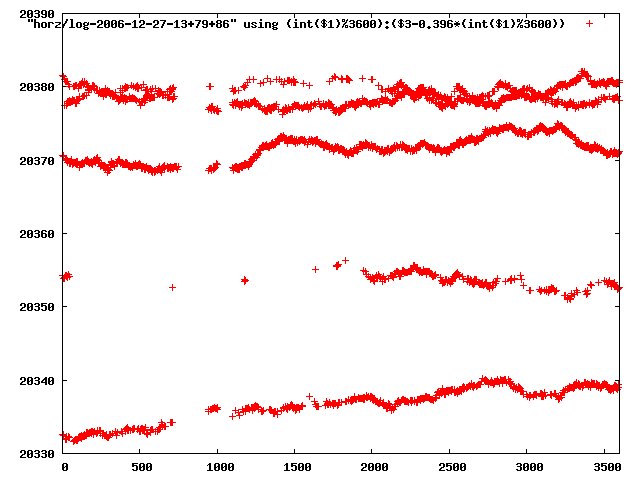
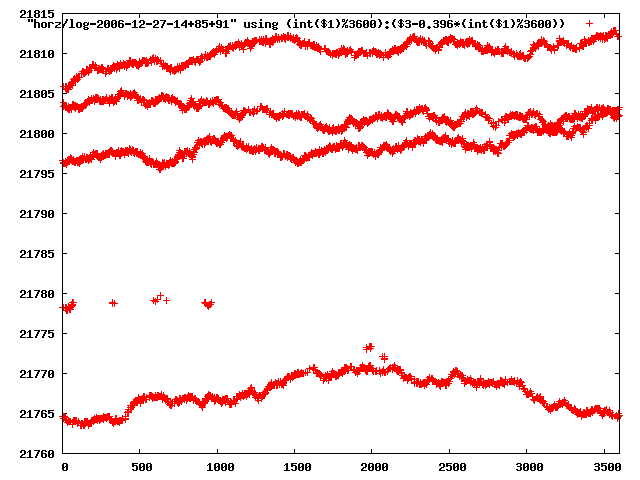
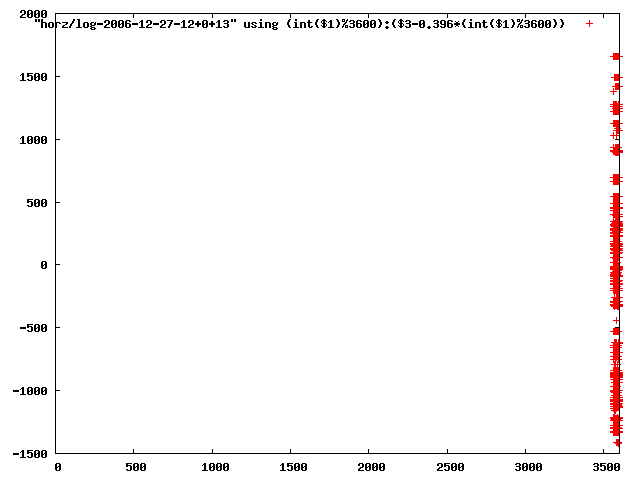
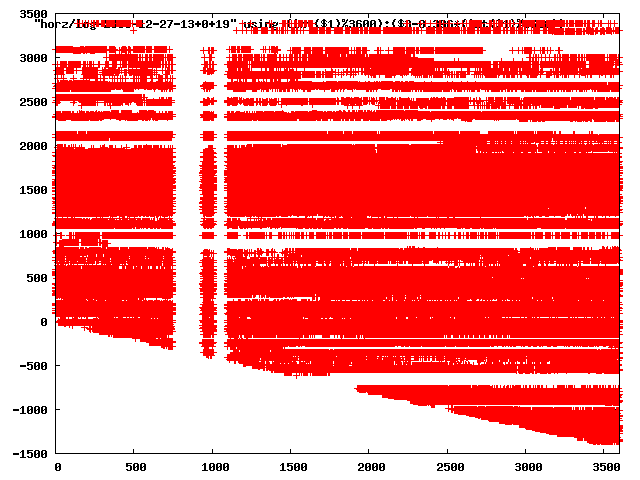
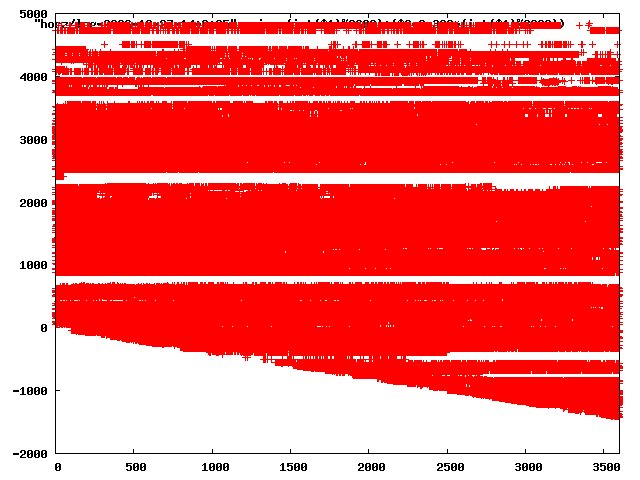
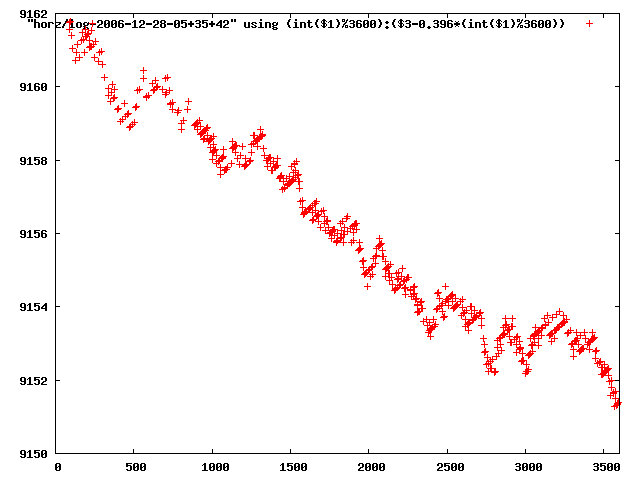
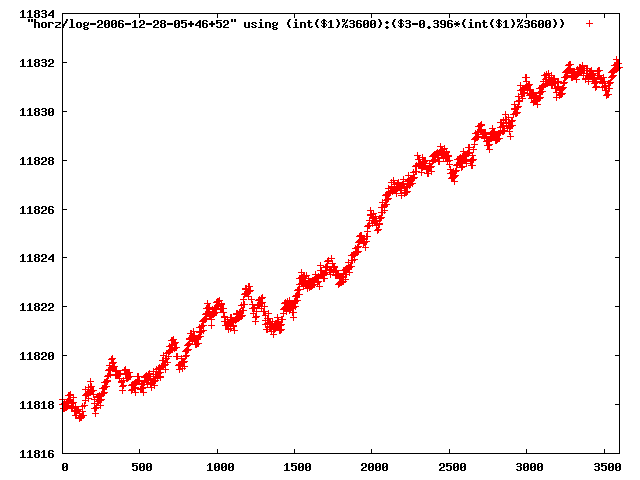
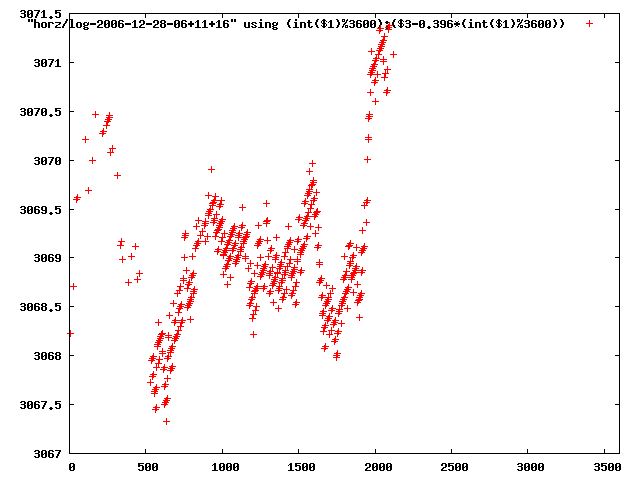
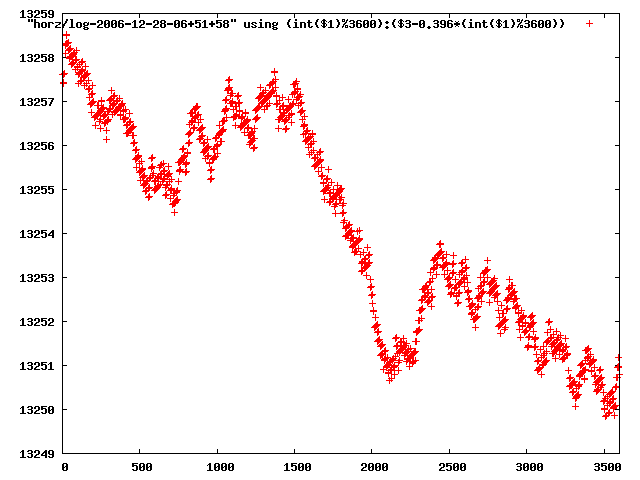
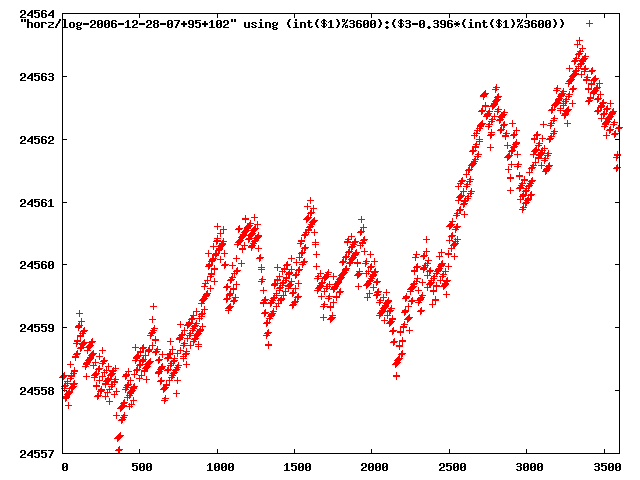
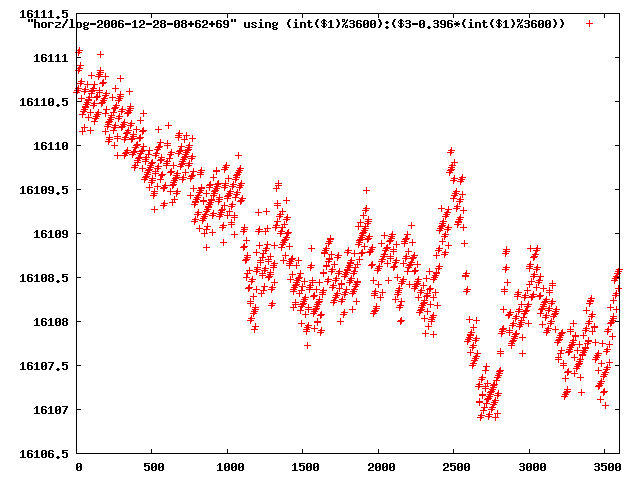
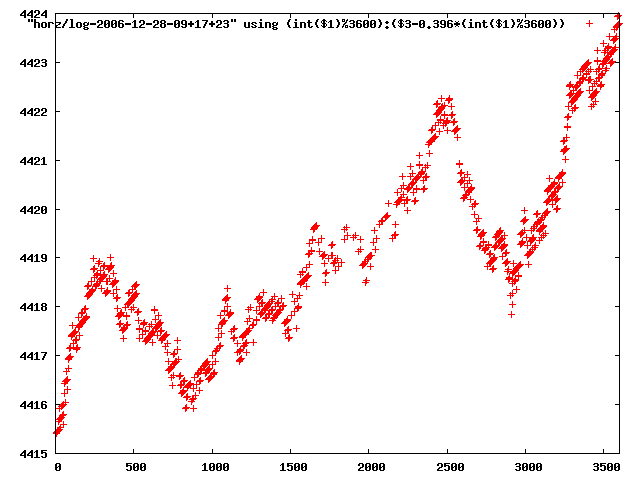
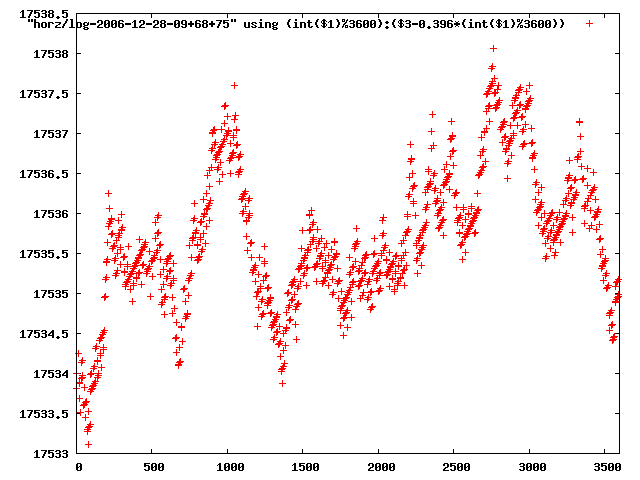
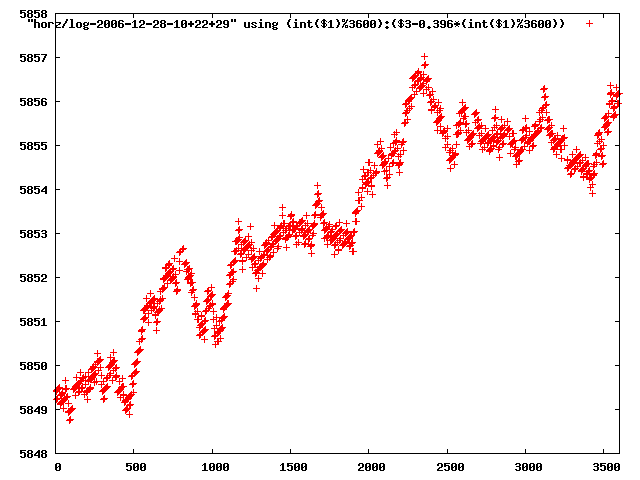
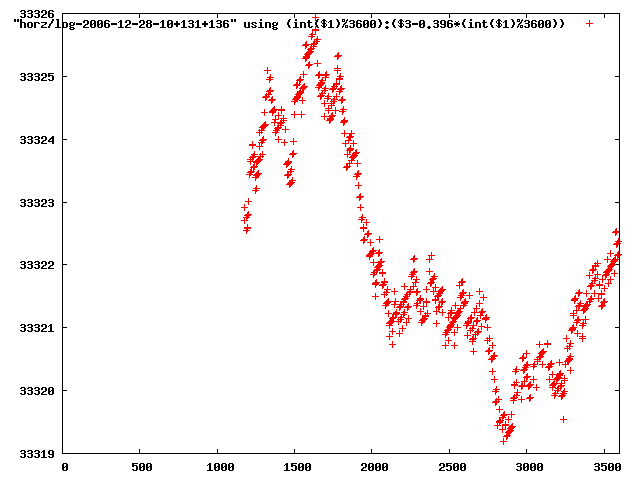
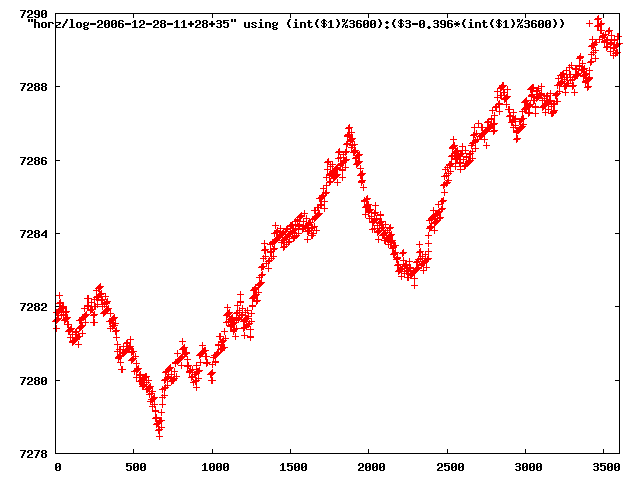
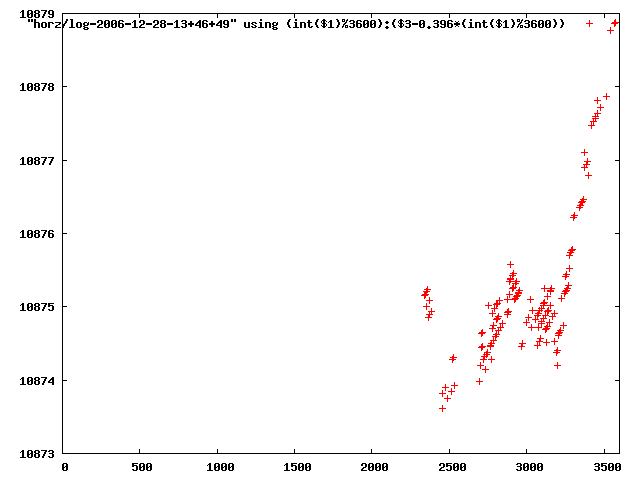
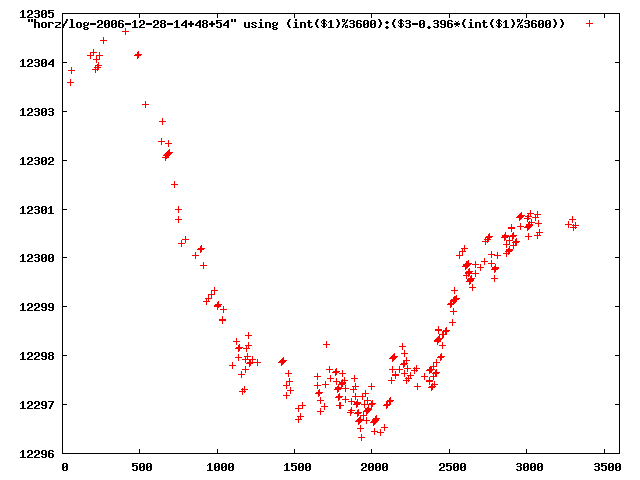
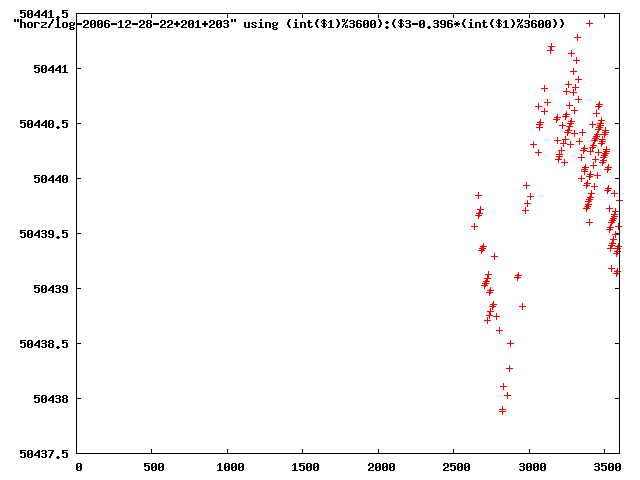
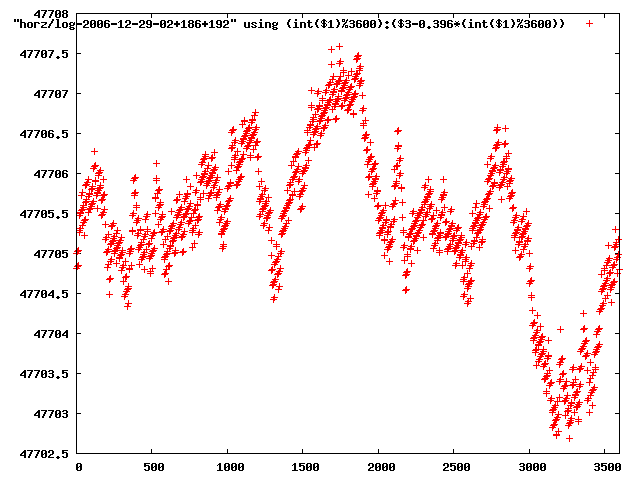
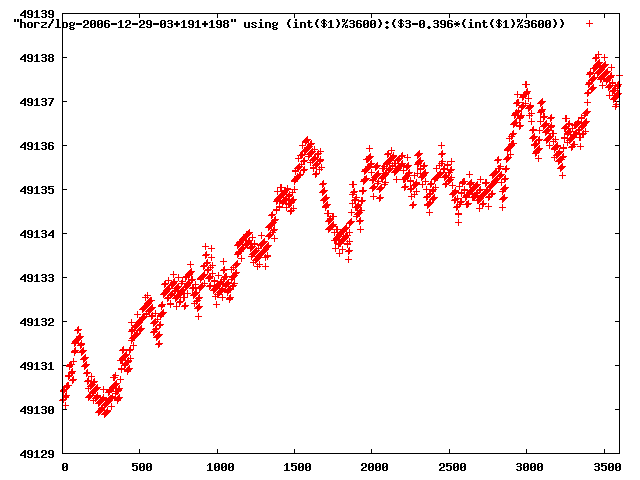
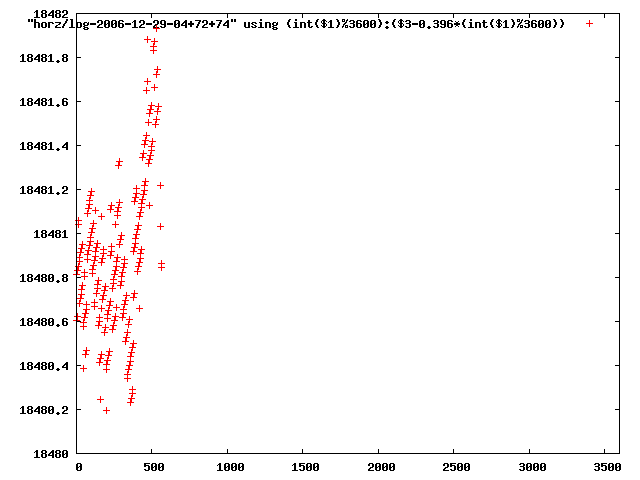
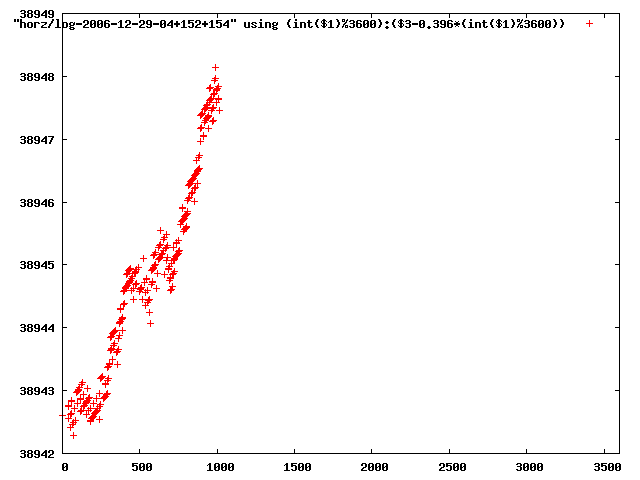
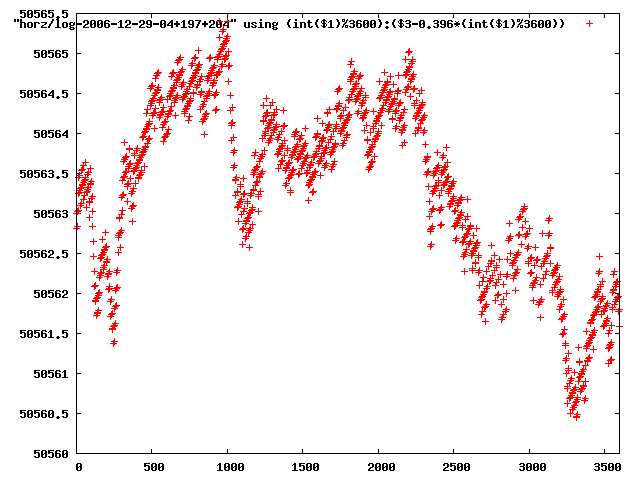
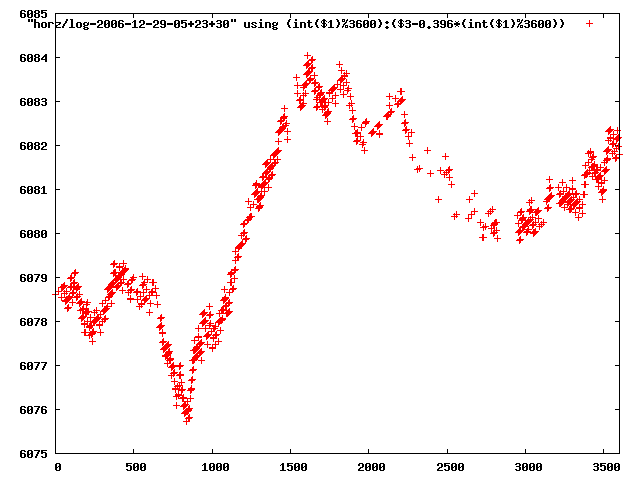
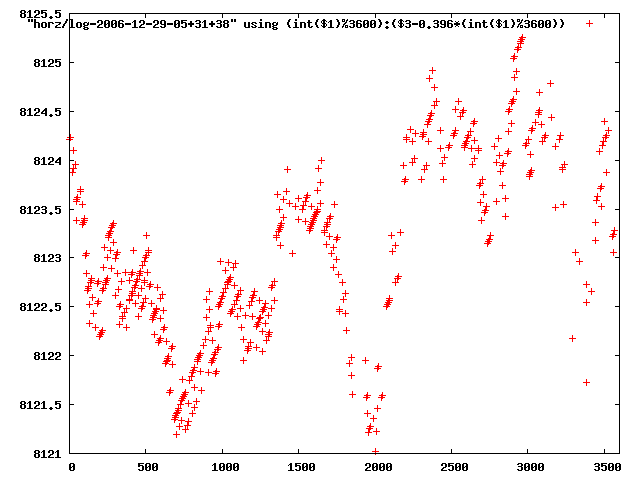
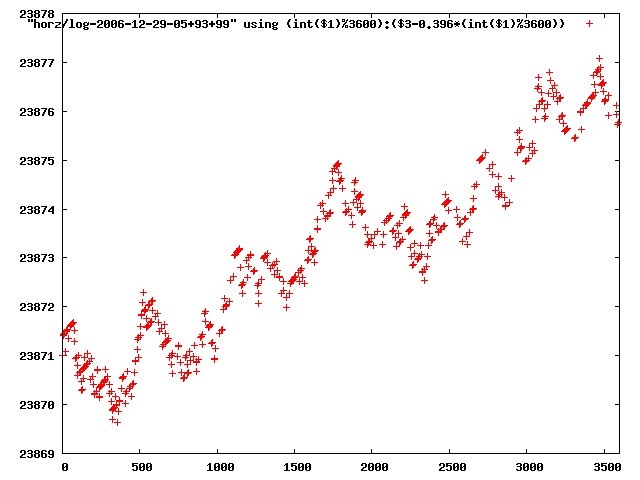
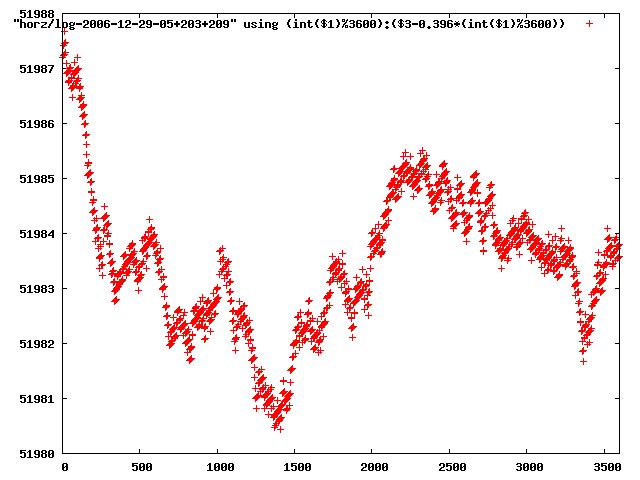
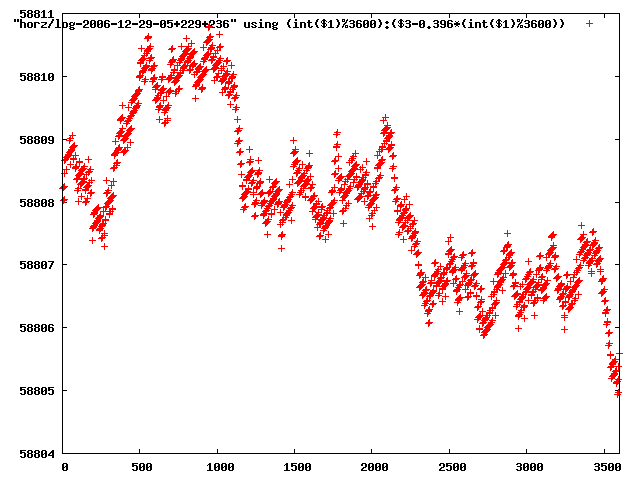
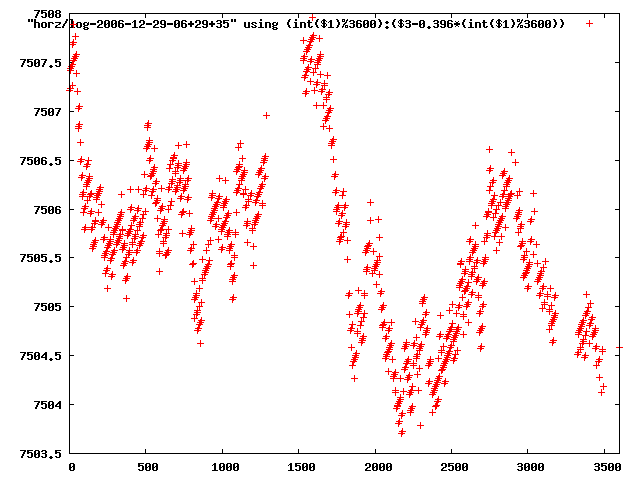
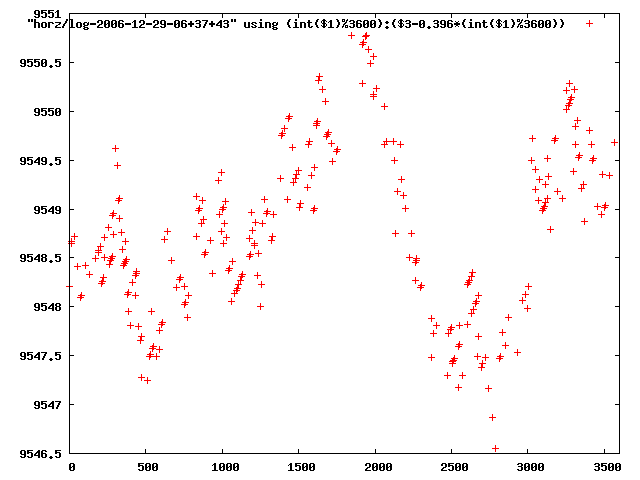
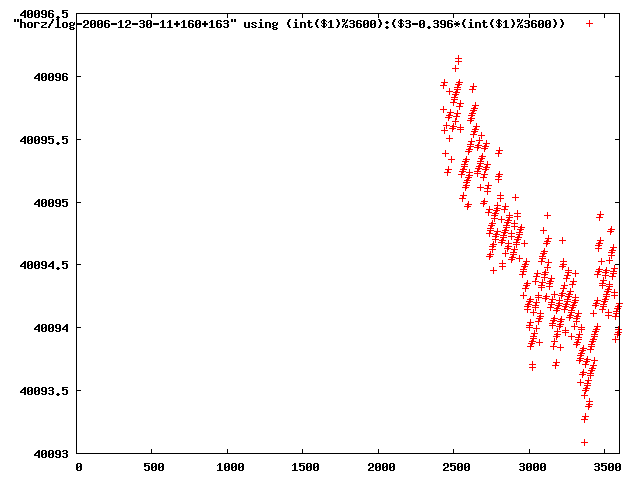
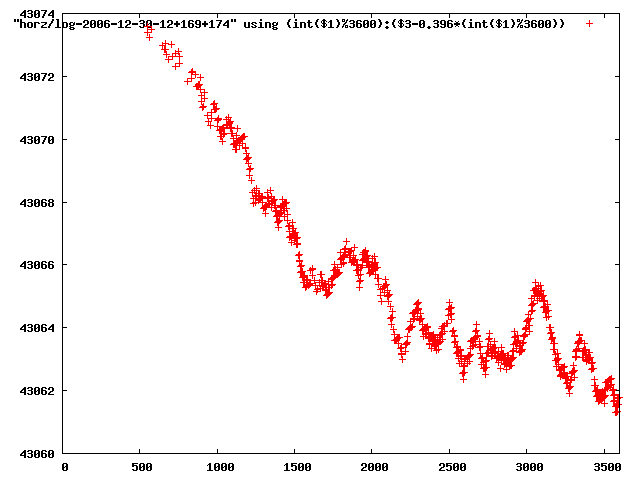
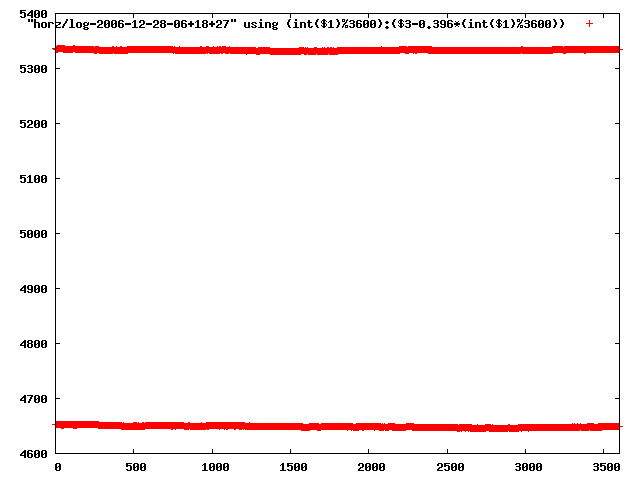
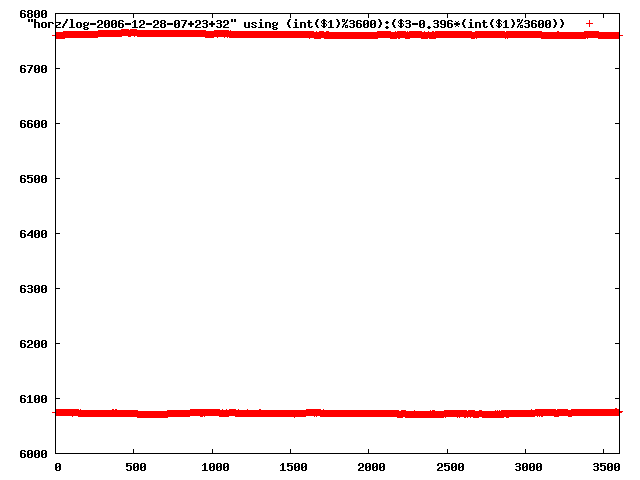
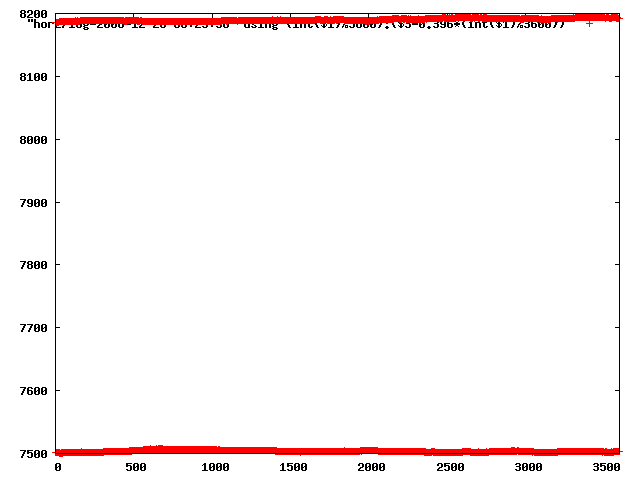
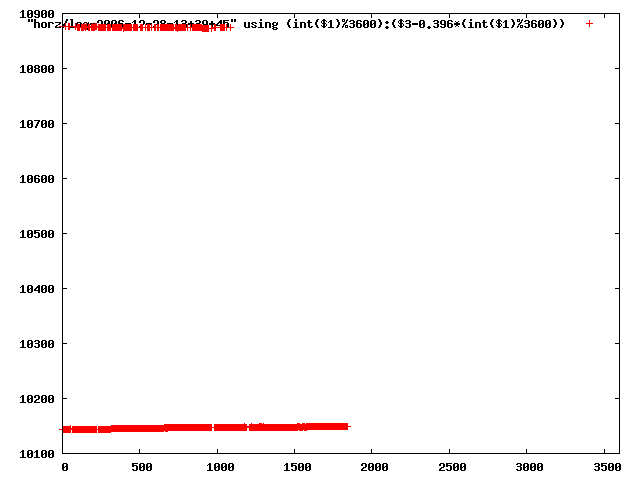
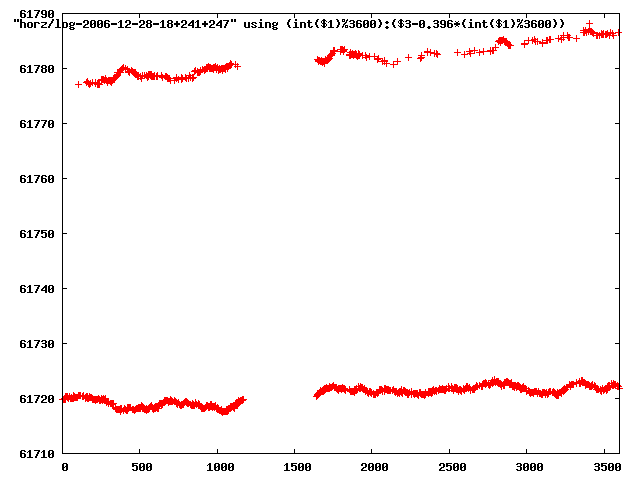
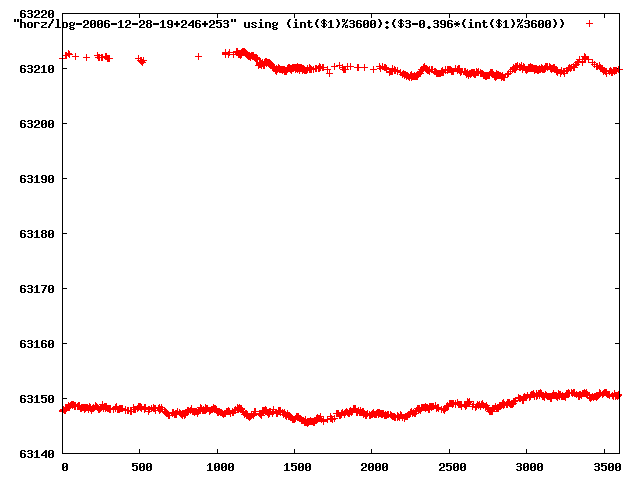
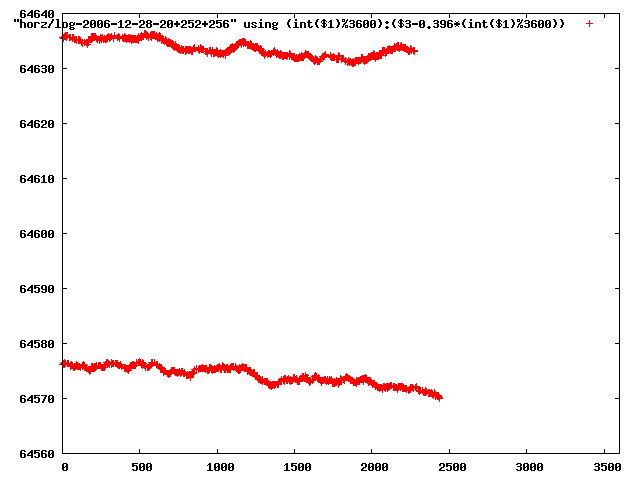
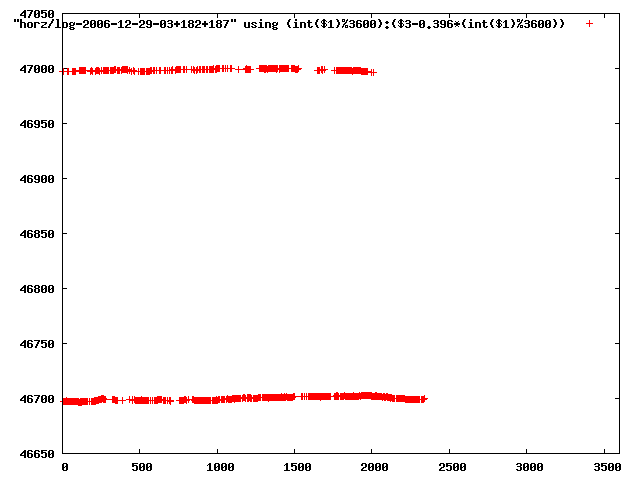
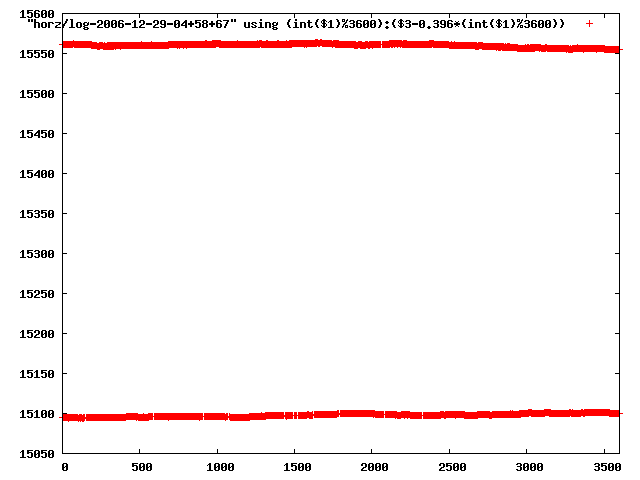
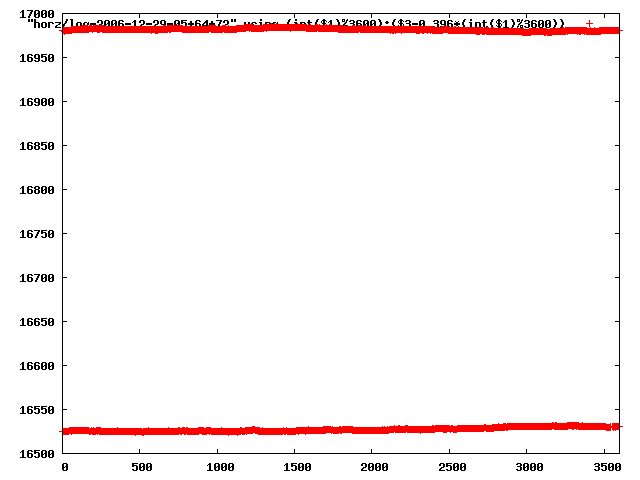
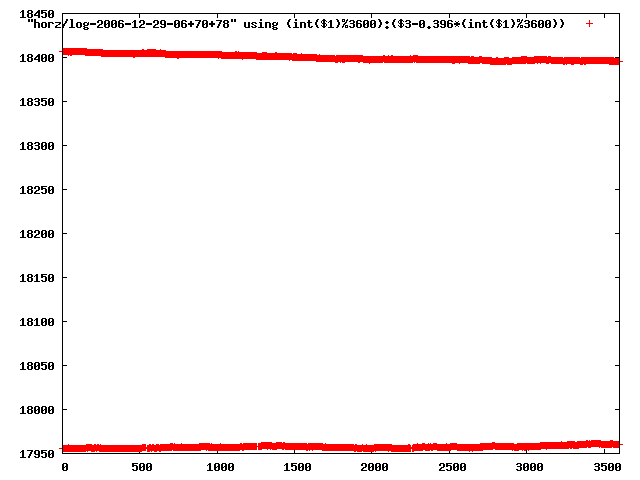
now split using slope:
mkdir rotated find binlog -type f | xargs ./rdlog -stations stationlist.txt -split rotated -slope 0.396 perl gengp.pl rotated pngrot > rot2png.gp gnuplot rot2png.gpthis generates 17849 seperate files